
Explain The Tweet: Japanese Language Edition

I’m a wannabe Twitter comedian, but often times my jokes require what some might call elite ball knowledge. So, welcome to the first installment of “Explain The Tweet”, a mini blog-series where I explicate my best work. Maybe we’ll learn something cool along the way!
This is the 🍙 Japanese Language edition, dedicated to my jokes about my favorite target language.
1. Moraic Timing and Sabrina Carpenter
To understand this joke, we need a crash course on Japanese phonetics. Let’s first talk about timing in languages.
English is stress-timed, meaning you’ll spend a roughly equal amount of time pronouncing sounds between each stressed syllable. Try this:
I’M deVELoping A NEW appliCAtion.
If you’re a native English speaker, you probably sped up the unstressed syllables to maintain a constant interval between each stressed syllable. Try pronouncing the sentence, but allot an equal time for each syllable, regardless of it’s stress. You sound like a robot.
Interestingly, languages like Spanish are indeed syllable-timed, which means native speakers do allot an equal amount of time for each syllable, regardless of stress.
Now we get to Japanese. Japanese is neither syllable-timed nor stress-timed; it is mora-timed. What is a mora, you might ask? Well, just like the syllable is the basic building block of English, the mora is the building block of Japanese.
Let’s look at the loanword sensei (yes, like what you would call your karate teacher, but also any other teacher for that matter). You might split the word into two syllables: sen / sei. However, a native Japanese speaker would split it into four mora: se / n / se / i. This moraic timing is so innate to the language that it is embedded into the writing systems. Notice how there are four characters, each corresponding to one mora: せんせい.
The nasal sound “n”—the only final-position consonant in the language—is allotted its own mora. The extended vowel “sei” (which may or may not be pronounced as a diphthong depending on where the speaker is from) is allotted two mora—two units of time.
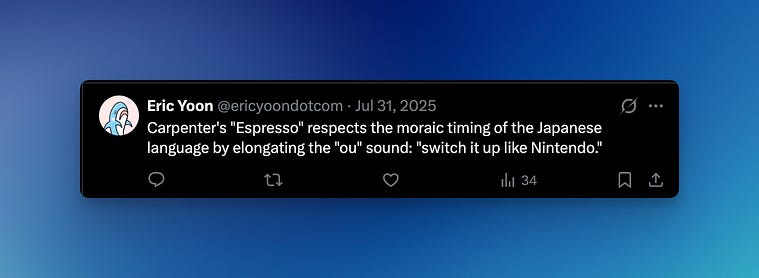
And now we have the requisite elite ball knowledge to understand the joke! The video game company Nintendo is spelled 「任天堂」; or in a syllabary, 「にんてんどう」. Each character corresponds to ni / n / te / n / do / u respectively.
Just like the “sei” in sensei takes up two mora, the “dou” in Nintendo takes up two mora. (And, in fact, Nintendo should be properly romanized as “Nintendou” if it were started any time after 1908). So, to respect the moraic timing, the dou should take two units of time to pronounce.

And look at that: Carpenter chose to elongate the “dou” when pronouncing “switch it up like Nintendo” in her hit song “Espresso”!
We briefly touched on romanization, but now it’s time to explore that topic in depth… are you ready?
2. Traditional vs. Modified Hepburn and the Performative Male
We looked at loanwords like sensei and proper nouns like Nintendo. Have you ever wondered: when a new word gets imported from Japanese into English, how do we convert the Japanese characters into Latin characters?
Well, there are various different answers, depending on whom and when you ask. Let’s look at the word 「社長」(しゃちょう).
If you ask the Japanese government for an official romanization, they are required by law to give you “syatyô”. This became official because it was standard in Japan during the time the law was written. However, if you showed this romanization to an English speaker without any Japanese knowledge, they will probably pronounce it wildly wrong.
To combat this, Christian missionary and Japanophile (read: OG weeb) James Curtis Hepburn introduced a new romanization system. This system was designed so that English speakers encountering these romanized words would instinctually pronounce them quite closely to their original Japanese pronunciations. So, our word would become “shachō” (with the macron indicating a long vowel, as previously discussed). This is much closer to the original pronunciation!
While the Hepburn system was introduced in 1867, it was revised in 1908. The original version is known as “traditional Hepburn” while the revised version is “modified Hepburn.” One difference is the treatment of the nasal 「ん」, so your favorite battered and deep-fried seafood (天ぷら) would be “tempura” in traditional, but “tenpura” in modified. (The former reflects the assimilation of the nasal consonant, while the latter is just simpler.)
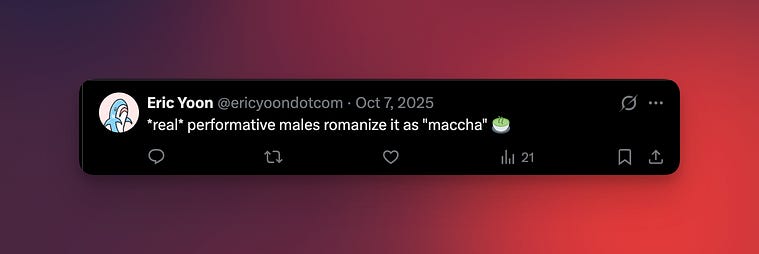
Back to the joke. Just like vowels can be extended (like “sei” in “sensei” and “dou” in “Nintendou”), consonants can also be extended to take up two mora. Your favorite green drink 「抹茶」(まっちゃ)has a 「っ」character in it, elongating the following consonant. In Hepburn, this would be romanized as “matcha” (with the elongated “ch–” sound being rendered as “tch–”). However, if you were a true performative male and cared about the integrity of the Japanese language, you would romanize it with Kunrei-Shiki as “maccha” (in “situations for which prior precedent would make a sudden reform difficult”), or “mattya” (if you were really willing to die on this hill).
We’ve focused on the syllabary writing systems of Japanese, but now let’s pay attention to the Chinese characters!
3. Radicals and the Zero-Width Joiner
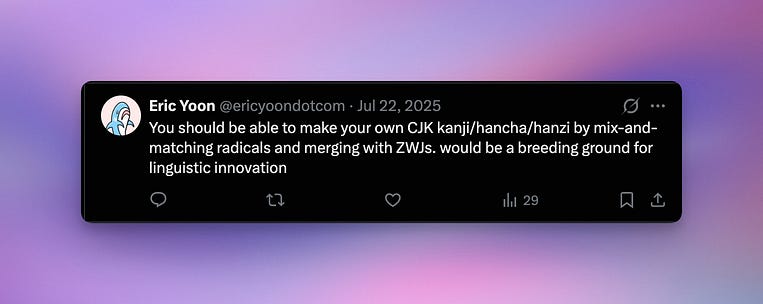
As you may know, many languages other than Chinese use Chinese characters. Korean used to have them in the form of hancha, until my GOAT King Sejong the Great banished them. Japanese still has them in the form of kanji.
Chinese characters are built on the mixing-and-matching of radicals—symbolic or ideographic building blocks. For example, you’ll see the radical 氵, meaning water, on the characters 「海」(ocean) and「酒」(alcohol).
Pivoting for a second, let’s talk about emoji. Open Twitter and type the 😶🌫️ (face with clouds) emoji 280 times. 280 is the character limit for a tweet… so why can’t we tweet 280 😶🌫️ emoji?
It turns out that 😶🌫️ is represented as two separate characters, 😶 (face without mouth) and 🌫️ (fog), merged together with a Zero Width Joiner. This Zero Width Joiner (ZWJ) is a special character defined by Unicode (not Yoonicode) that allows the combination of characters to create a new one. Since it is “zero width”, it doesn’t actually get rendered on the screen—it is a special instruction to your computer’s text renderer!
So, my great idea: what if we could use ZWJs to merge any radical we want? For example, what if you could combine the 串 (skewer) character with the 手 (hand) radical to represent skewers that you pick up with your hand? Or maybe you’ll combine it with the 鳥 (bird) radical to specify poultry-related kebabs. This would open the floodgates for linguistic innovation in China, Japan, and any other country that uses CJK (Chinese, Japanese, Korean) characters.
Isn’t it lovely that the character for skewer looks just like a kebab? Now I’m hungry… 串串串
Conclusion
You’re here because you wanted three jokes explained to you… but you’ve left with new knowledge on Japanese phonetics, romanization, and even some technical details of UTF-8. I’d call that a win!
Stay tuned for the next installment of “Explain The Tweet.” Subscribe so you don’t miss it!